
DIVOTrack: A Novel Dataset and Baseline Method for Cross-View Multi-Object Tracking in DIVerse Open Scenes
Shengyu Hao, Peiyuan Liu, Yibing Zhan, Kaixun Jin, Zuozhu Liu, Mingli Song, Jenq-Neng Hwang and Gaoang Wang
International Journal of Computer Vision (IJCV), 2023
[Paper]
[Dataset]
[Code]

A new cross-view multi-object tracking dataset for DIVerse Open scenes with dense tracking pedestrians in realistic environments.

StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu
International Conference on Computer Vision (ICCV), 2023
[Website]
[Paper]
[Demo]
[Code]

We tackle introduce temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the new objects.
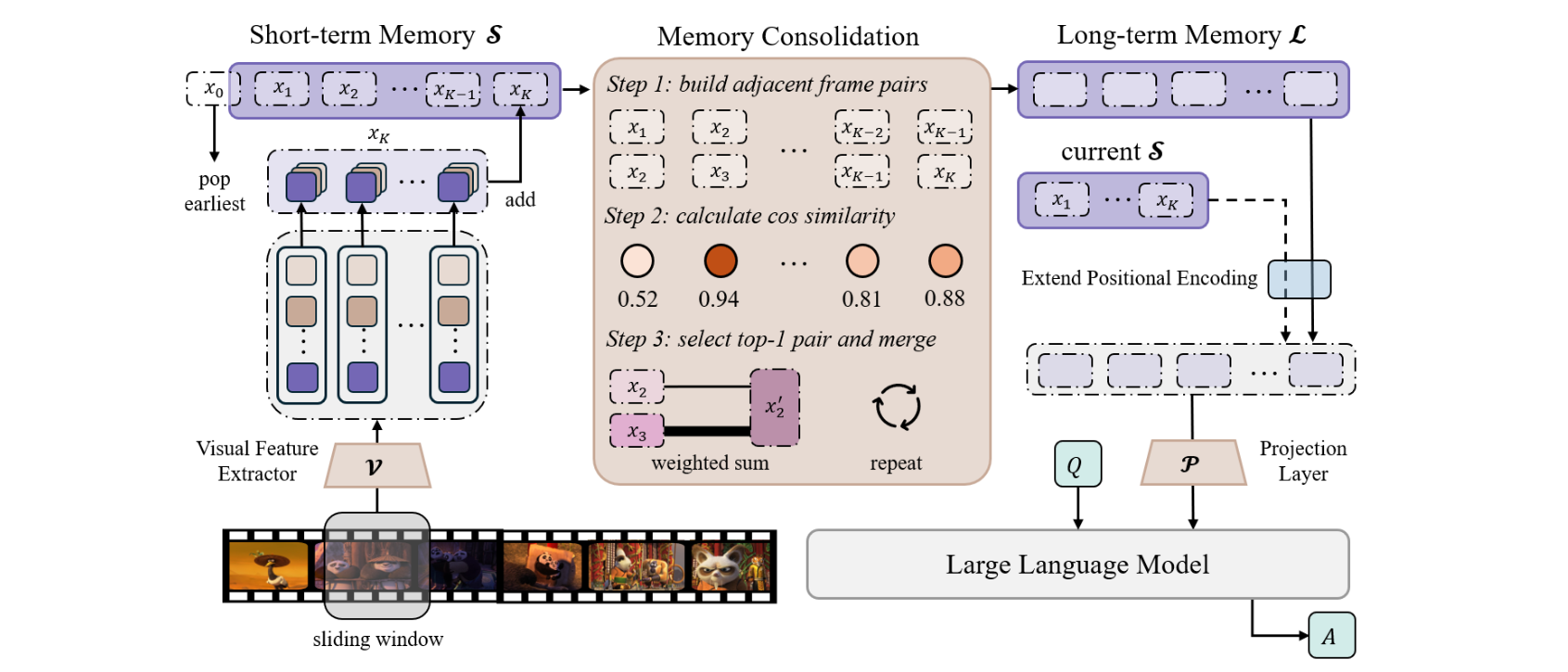
MovieChat: From Dense Token to Sparse Memory in Long Video Understanding
Enxin Song*, Wenhao Chai*♡, Guanhong Wang*,Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Tian Ye, Jenq-Neng Hwang, Gaoang Wang✉
arXiv Preprint.
[Website]
[Paper]
[Dataset]
[Code]

MovieChat achieves state-of-the-art performace in long video understanding by introducing memory mechanism.